


智东西
作者 | 程茜
编辑 | 心缘
智东西3月12日报道,昨日,阿里通义实验室开源R1-Omni模型——业界首个将具有可验证奖励的强化学习(RLVR)应用于全能多模态大语言模型。
研究人员利用RLVR对开源Omni模型HumanOmni-0.5B进行优化,在推理能力、情感识别准确性和泛化能力三个关键方面显著提高了其性能。
R1-Omni能够更清楚地理解视觉和听觉信息如何促进情绪识别,能够明确展示哪些模态信息对特定情绪的判断起到了关键作用。与SFT(传统监督微调)相比,RLVR显著提高了情绪识别任务的性能,在同分布测试集(DFEW和MAFW)上,R1-Omni相较于原始基线模型平均提升超过35%,相较于SFT模型在UAR上的提升超10%。
RLVR是DeepSeek项目中的一种强化学习方法,其核心思想是利用验证函数直接评估输出,无需依赖单独的奖励模型。此前,RLVR研究多聚焦于图像、文本等多模态任务重,尚未涉足更复杂的全模态场景。
阿里通义团队选择开源Omni模型HumanOmni-0.5B作为基础模型,目前已经开源了基本模型HumanOmni-0.5B、冷启动模型EMER-SFT、直接在MAFW和DFEW训练集上微调的模型MAFW-DFEW-SFT,以及最终模型R1-Omni。
论文:https://arxiv.org/abs/2503.05379
Github:https://github.com/HumanMLLM/R1-Omni
模型:https://www.modelscope.cn/models/iic/R1-Omni-0.5B
一、充分理解音视频,给出模态信息与特定情绪对应关系
R1-Omni的一大亮点在于其透明性(推理能力)。通过RLVR方法,模型可以充分理解音频信息和视频信息并判断人物的情绪,论文中给出了下面两个示例:
指令:作为情绪识别专家,在整个视频中角色传达的哪种情感对你来说最明显?将思考过程输出到中,将最终的情感输出到中。
HumanOmni-0.5B:恐惧
EMER-SFT:在视频中,一名身穿棕色夹克的男子站在一幅充满活力的壁画前,他的脸上明显流露出愤怒的迹象。他皱起的眉毛和张开的嘴巴表达了他的不满。从他的表情和发声特征可以推断出他正在经历情绪动荡。音频内容提到了“恐惧”和“降低声音”,暗示他正面临紧急情况或在情绪紧张的时刻表现出强烈的情绪。总体而言,分析表明该男子正在经历一种深深的害怕和焦虑感。
MAFW-DFEW-SFT:生气
R1-Omni:在视频中,一个穿着棕色夹克的男人站在一幅充满活力的壁画前。他棕色夹克下面穿着一件粉红色的衬衫,头发又黑又卷。他的面部表情复杂,睁大眼睛,微微张开嘴巴,眉毛上扬,眉头紧皱,透露出惊讶和愤怒。语音识别技术表明,他的声音中包含“你”、“降低你的声音”、“freaking out”等词,表明情绪强烈和激动。总体而言,他表现出困惑、愤怒和兴奋的情绪状态。
指令:作为情绪识别专家,在整个视频中角色传达的哪种情感对你来说最明显?将思考过程输出到中,将最终的情感输出到中。
HumanOmni-0.5B:快乐
EMER-SFT:在视频中,我们看到一名女性在室内环境中,似乎是个人空间或自习室。她戴着红色头带,白色上衣外面套着米色西装外套,头发整齐地扎在后面。她的面部表情流露出些许困惑和惊讶,仿佛遇到了什么意想不到的事情。随着时间的推移,她的情绪似乎平静了下来,但具体原因并没有解释。在音频中,“but”和“it was”之间有一段长时间的沉默,表明了犹豫和不确定。在文本中,副标题写道:“但这很有趣。这句话可能表达了这个人的困惑和惊讶。根据女子略带困惑和惊讶表情的视频线索,以及她整体的外表和面部表情呈现出轻微的困惑和惊讶,我们可以推断出这句话可能带有犹豫或不定的语气。此外,描述“but”和“it was”之间长时间沉默的音频线索也表明了一些犹豫和不确定性。因此,这句话表达了女人对某事的兴趣和好奇,而also则表现出一定程度的犹豫和不确定。
MAFW-DFEW-SFT:快乐
R1-Omni:在视频的开场场景中,我们看到一个女人微微闭着眼睛,嘴巴慢慢张开,仿佛她正在预示。她的面部表情看起来有些喜悦,这可能表明她在那一刻正在经历一些愉快或有趣的情况。在音频中,句子之间没有停顿,它们连续流动,语气轻盈欢快。结合文字内容,可以感觉到角色处于非常快乐和积极的情绪状态。在文本中,副标题写道:“这很有趣。这句话可能表达了女人对某事或某人的满意和好奇。根据视频线索中女子所表现出的笑声和喜悦的表情,以及音频线索中对连续流淌、轻盈欢快的语气的描述,我们可以推断出这句话表达了女子对某事的兴趣和好奇。这句话中的喜悦与幸福和积极的整体表现是一致的。
二、推理、情感识别、泛化能力提升,相较原始基线模型平均提升超35%
研究人员利用RLVR对Omni模型进行优化后,模型在推理能力、情感识别准确性和泛化能力三个关键方面提高了性能。
首先,最初的HumanOmni-0.5B和MAFW-DFEW-SFT模型表现出有限的推理能力。EMER-SFT的推理过程连贯性相对较差,容易产生幻觉。例如,在MAFW和DFEW数据集上进行测试时,R1-Omni通过提供更连贯、更准确和可解释的推理过程,始终优于这些基线。
其次,为了定量评估R1-Omni的理解能力,研究人员将其性能与主要由电影剪辑组成的MAFW和DFEW数据集上的其他模型进行了比较。用于评估的指标是未加权平均召回率(UAR)和加权平均召回率(WAR),它们衡量模型对不同类别的情绪进行准确分类的能力。
在此设置中,模型没有提供预定义的情感类别,而是直接从输入数据生成情感标签。
实验结果显示,在同分布测试集(DFEW和MAFW)上,R1-Omni相较于原始基线模型平均提升超过35%,相较于SFT模型在UAR上的提升高达10%以上。在不同分布测试集(RAVDESS)上,R1-Omni在WAR和UAR均提升超过13%。
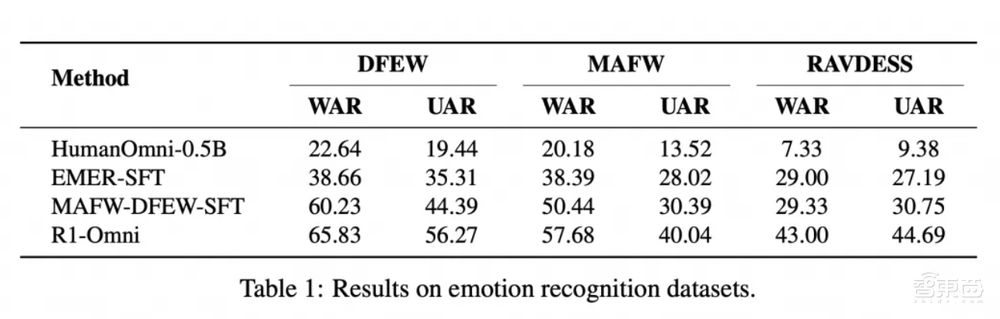
更直观的比较如下:
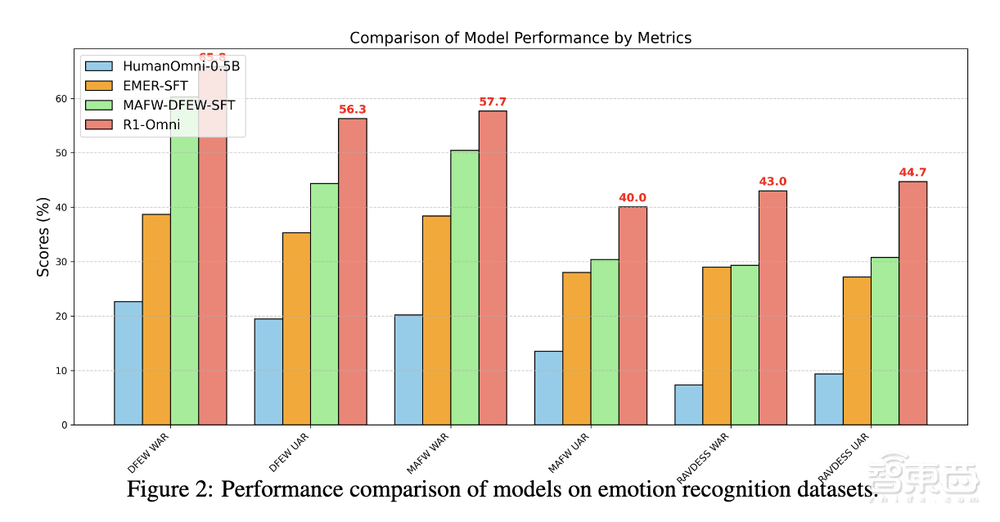
最后是R1-Omni的泛化能力,研究人员在RAVDESS数据集上进行实验,该数据集用作分布外(OOD)测试集,RAVDESS数据集的特点是专业演员以中性的北美口音说出词汇匹配的陈述。数据分布的这种显著差异使RAVDESS成为评估模型泛化到看不见场景的能力的理想基准。
三、冷启动+RLVR训练阶段,提升模型情绪识别准确度
模型训练包括两个阶段。
第一个是冷启动阶段,为了保证RLVR阶段训练的平稳性,该团队使用一个组合数据集进行微调,使其初步掌握多模态情感识别任务中的推理能力。该组合数据集是由580条视频数据组成的组合数据集,其中包括来自Explainable Multimodal Emotion Reasoning(EMER)数据集的232条样本,以及来自HumanOmni数据集的348条样本。
这一阶段确保了模型在进入RLVR阶段前已具备一定基础能力,从而提升后续训练的效率与稳定性。
冷启动阶段使用的EMER数据的具体格式如下所示。

第二个是RLVR阶段,实现推理与泛化能力双重提升,这一训练过程旨在优化HumanOmni-0.5B使用包括视频和音频数据的多模态输入进行情绪识别任务。
基于冷启动阶段初始化的模型,通过RLVR的方式训练,同时利用视频和音频的多模态数据优化情感识别任务。该阶段通过强化学习与可验证奖励机制,进一步优化模型的推理能力和泛化性能。
RLVR的第一个关键组件是策略模型(policy model),该模型处理由视频帧和相应音频流组成的多模态输入数据,并生成一组候选响应。每个响应都附带详细的推理,展示了模型如何整合视觉和听觉信息从而得出预测的详细过程。
第二个关键组件是奖励函数,策略模型生成的这些候选响应使用可验证的奖励函数(reward function)进行评估。RLVR训练框架中用到的奖励函数受DeepSeek-R1的启发,将奖励分成了两个部分,精确率奖励(accuracy reward)和格式奖励(format reward),这两部分共同形成最终的奖励R:
准确值奖励的计算方式如下:
通过联合两部分奖励,该奖励函数不仅鼓励模型生成正确的预测,同时保证输出是结构化的,并且和其预设格式一致。
实验表明,RLVR不仅让音频和视频信息的作用更加透明,还显著提升了模型在情绪识别任务中的关键指标。
四、仍有局限,字幕识别不准、幻觉、语调线索利用率低
R1-Omni仍存在一些需要进一步研究的局限性,论文中提到了三个具有代表性的示例:
第一个例子中,尽管模型产生了正确的情绪预测,但其字幕识别并不准确,解决这一限制需要集成更强大的字幕处理技术,例如对专业数据集进行微调或整合高级自然语言理解模型。

第二个示例演示了一个常见的问题幻觉,模型生成的推理输出不基于视频的实际内容。例如,“画外音揭示了她中立的最初反应,随着时间的推移逐渐变成轻微的兴奋和愤怒”这句话与视频的实际情绪轨迹不一致。这种捏造的推理导致模型错误地将情绪预测为惊喜。

第三个示例强调了该模型充分利用音频线索(如语气和语调)的能力有限,而音频线索对于准确的情绪识别至关重要。尽管模型能够通过整合音频和视频信息来推理情绪,但在某些情况下,音频特征的使用似乎不如使用视觉线索彻底或有效。在这个特定实例中,角色的声音传递提供了强烈的情感信号,但该模型未能将这些细微差别充分纳入其推理过程。

结语:RLVR加速多模态任务研究
RLVR方法的出现,为多模态任务提供了全新的优化思路,无论是几何推理、视觉计数,还是经典图像分类和物体检测任务,RLVR都展现出了显著优于传统监督微调(SFT)的效果。
基于当下研究的局限,研究人员在论文中提到了未来几个研究方向:
1、加强基础模型的能力。虽然RLVR显著增强了基础模型的推理和泛化能力,但基础模型的固有性能仍然是整体成功的关键决定因素。
2、减轻推理输出中的幻觉。由于多模态数据固有的挑战,例如视频和音频令牌中的因果关系比文本Token弱,以及缺乏对推理内容的明确监督,在模型的推理过程中可能会出现幻觉。开发检测和减轻幻觉的机制对于提高模型的可靠性和可用性至关重要。
3、提高音频线索的利用率。例如音调和语调等的利用率不足代表了当前模型的局限性,未来的工作应侧重于提高模型有效提取和集成音频特征的能力。
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






